基于YOLOv6-水下垃圾检测 记录一下第一次跑通的深度学习模型。
概述 此篇文章介绍基于YOLOv6 自定义数据集训练—水下垃圾检测。在谷歌硬盘中完成训练。
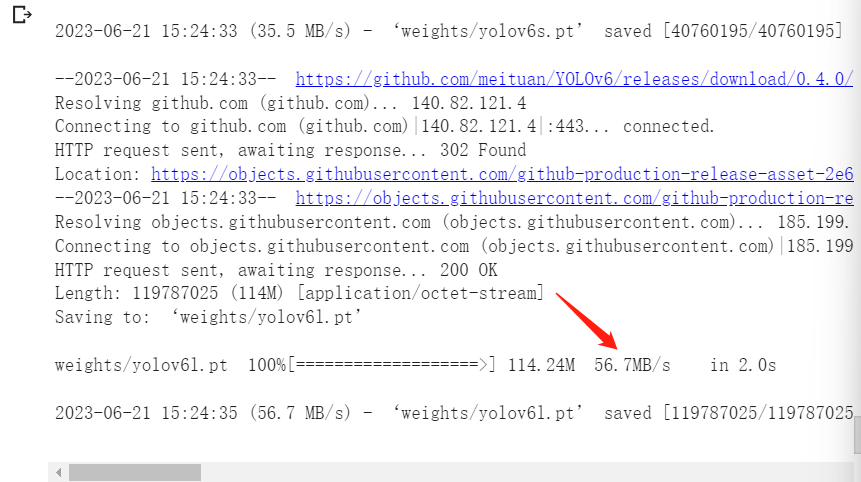
为什么使用谷歌硬盘 1,谷歌硬盘的下载速度特别给力,基本上都是几十mb/s。
如图的下载速度
2,谷歌免费提供GPU硬件支持。
当然谷歌硬盘也有不足的地方,首先是访问它就有门槛,然后是免费用户最多一次性运行十二小时。
正文 代码来源与介绍,如果你想了解更多信息,请访问此网站。
YOLOv6 自定义数据集训练 – 水下垃圾检测 (learnopencv.com)
代码下载链接
https://www.dropbox.com/scl/fo/ppvl9zhiip2oy81b84yzi/h?dl=1&rlkey=wsmw1604zqdcvg8z05pfr2ohd
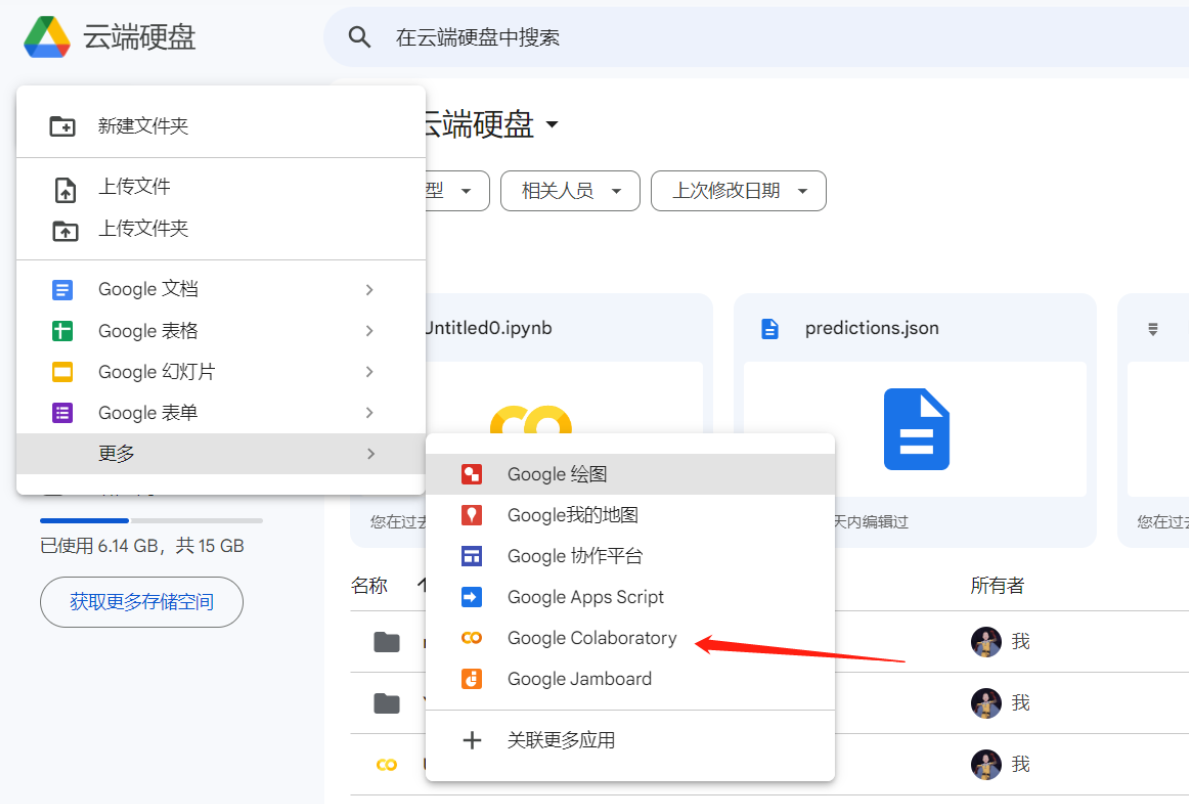
谷歌硬盘的使用 打开谷歌硬盘后,点击新建
选择更多中的Google Colaboratory
这样就生成了一个.ipynb的文件,而且有jupyter页面,你可以在这里面开始训练你的模型了!
创建好文件后要点击连接,这样你才能分配到资源,来跑你的代码
这个选项可以挂载到你的谷歌硬盘上面
注意事项 一定要先点击这个修改里面的笔记本设置
将硬件加速改为GPU,我当时默认的是无,因此走了好多弯路
注意:如果你在运行代码的时候点击了保存,那么将会断开连接,你运行的代码,可能要重新运行了。
小经验 在jupyter中想运行终端命令该如何运行呢?
我目前接触到了两个符号
如果你想克隆GitHub仓库,那你需要在指令前面加上 !如
1 !git clone https://github.com/meituan/YOLOv6.git
下载其他链接也是如此比如 ! wget …..
还有一个符号是%
如果你想看你的目录下有什么文件,你可以输入
你想移动到其他文件夹,请输入
指令是Linux常见指令,不过需要在前面加上符号
我增补后的代码介绍 训练前的准备 我在第一次训练模型时,发现直接运行会报错,提示信息是找不到tensorflow,所以我在网上找了下载tensorflow的方法。输入以下命令,就可以下载了。
1 2 3 4 5 6 7 8 !dpkg -i nv-tensorrt-repo-ubuntu1804-cuda10.0-trt5.1.2.2-rc-20190227_1-1_amd64.deb !apt-key add /var/nv-tensorrt-repo-cuda10.0-trt5.1.2.2-rc-20190227/7fa2af80.pub !apt-get update !apt-get install -y --no-install-recommends libnvinfer5=5.1.2-1+cuda10.0 !apt-get install -y --no-install-recommends libnvinfer-dev=5.1.2-1+cuda10.0 !apt-get install tensorrt !apt-get install python3-libnvinfer-dev !apt-get install uff-converter-tf
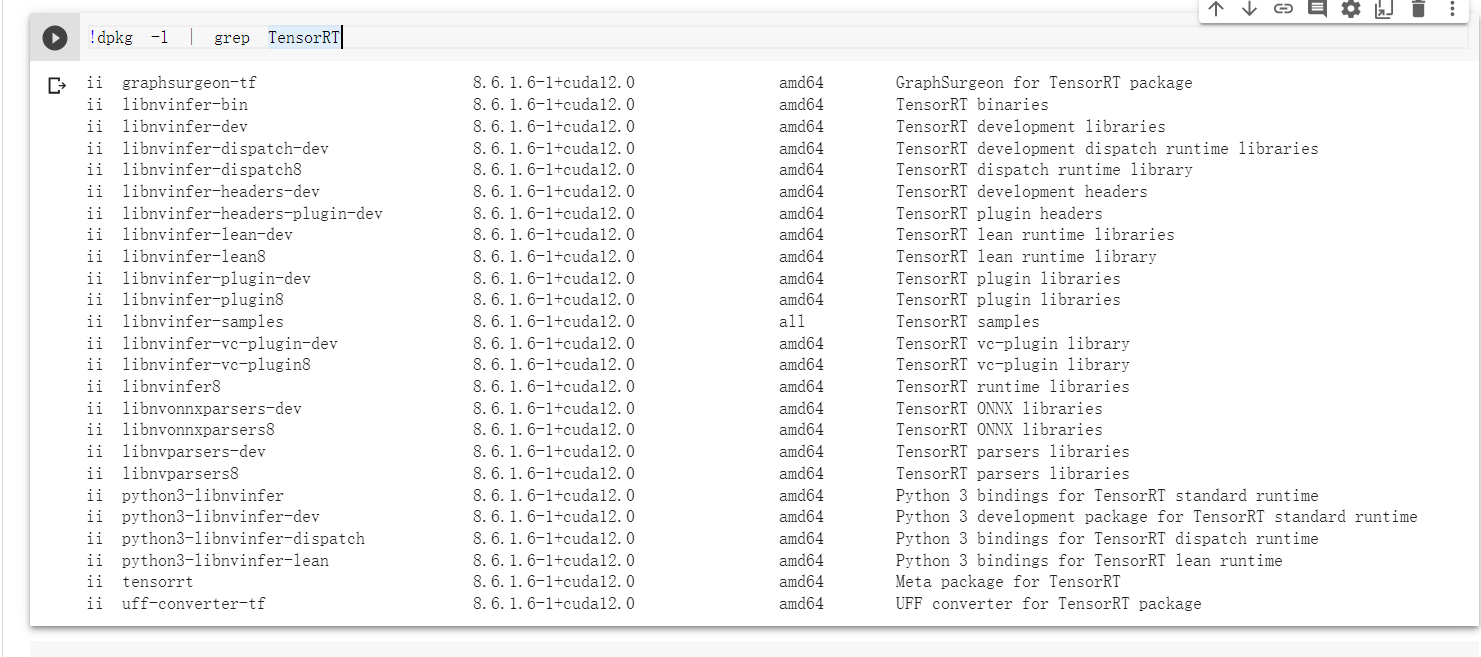
输入这行命令,就能检验你是否安装成功。
1 !dpkg -l | grep TensorRT
如何看你是否安装了torch和tensorflow呢?请输入这两个指令。
1 2 3 4 5 import torch torch.cuda.is_available() import tensorflow as tf tf.test.gpu_device_name()
如图,说明已经安装了,GPU:0,说明我们选择GPU的时候只有一个选择了,因为只有这一个GPU,而且这块GPU的代号是0,如果你有多个GPU,那么当你运行上面的代码时,会输出GPU:0,1,2类似的信息。
以上是我补充的代码,接下来就是Sovit Rath 写好的代码了
我来给大家解释一下代码的作用。
导入必需的库
1 2 3 4 5 6 7 8 import os import zipfile import requests import glob import cv2 import matplotlib.pyplot as plt import numpy as np import random
生成随机种子
1 2 SEED = 100 np.random.seed(SEED)
移动到指定目录,这个也是我自己加的,移动到指定的目录,会是你的文件管理更加清晰,安装的文件也清晰明了。
1 %cd /content/drive/MyDrive
克隆YOLOv6的 GitHub仓库
1 2 if not os.path.exists('YOLOv6'): !git clone https://github.com/meituan/YOLOv6.git
移动到仓库目录下
安装YOLOv6的依赖
1 !pip install -r requirements.txt
下载数据集
1 2 3 4 5 6 7 8 9 10 def download_file(url, save_name): url = url if not os.path.exists(save_name): file = requests.get(url) open(save_name, 'wb').write(file.content) download_file( 'https://www.dropbox.com/s/lbji5ho8b1m3op1/reduced_label_yolov6.zip?dl=1', 'reduced_label_yolov6.zip' )
解压数据集
1 2 3 4 5 6 7 8 9 10 # Unzip the data file. def unzip(zip_file=None): try: with zipfile.ZipFile(zip_file) as z: z.extractall("./") print("Extracted all") except: print("Invalid file") unzip('reduced_label_yolov6.zip')
将配置的文件写入仓库中,这个是自定义数据集的必须操作。
数据集所在的位置,数据集的类别信息,比如这个有四种,分别是animal’,’plant’,’rov’,’trash’,这些信息都需要写入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 %%writefile data/underwater_reduced_label.yaml # Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR train: 'reduced_label_yolov6/images/train' # train images val: 'reduced_label_yolov6/images/valid' # val images # whether it is coco dataset, only coco dataset should be set to True. is_coco: False # Classes nc: 4 # number of classes names: [ 'animal', 'plant', 'rov', 'trash' ] # class names
数据集的类别
1 2 3 4 5 6 class_names = [ 'animal', 'plant', 'rov', 'trash' ]
绘制图片框框的颜色
1 colors = np.random.uniform(0, 255, size=(len(class_names), 3))
转换数据集中的边界框,
1 2 3 4 5 # Function to convert bounding boxes in YOLO format to xmin, ymin, xmax, ymax. def yolo2bbox(bboxes): xmin, ymin = bboxes[0]-bboxes[2]/2, bboxes[1]-bboxes[3]/2 xmax, ymax = bboxes[0]+bboxes[2]/2, bboxes[1]+bboxes[3]/2 return xmin, ymin, xmax, ymax
接下来两段代码是绘制边界框的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 def plot_box(image, bboxes, labels): # Need the image height and width to denormalize # the bounding box coordinates height, width, _ = image.shape lw = max(round(sum(image.shape) / 2 * 0.003), 2) # Line width. tf = max(lw - 1, 1) # Font thickness. for box_num, box in enumerate(bboxes): x1, y1, x2, y2 = yolo2bbox(box) # denormalize the coordinates xmin = int(x1*width) ymin = int(y1*height) xmax = int(x2*width) ymax = int(y2*height) p1, p2 = (int(xmin), int(ymin)), (int(xmax), int(ymax)) class_name = class_names[int(labels[box_num])] color=colors[class_names.index(class_name)] cv2.rectangle( image, p1, p2, color=color, thickness=lw, lineType=cv2.LINE_AA ) # For filled rectangle. w, h = cv2.getTextSize( class_name, 0, fontScale=lw / 3, thickness=tf )[0] outside = p1[1] - h >= 3 p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3 cv2.rectangle( image, p1, p2, color=color, thickness=-1, lineType=cv2.LINE_AA ) cv2.putText( image, class_name, (p1[0], p1[1] - 5 if outside else p1[1] + h + 2), cv2.FONT_HERSHEY_SIMPLEX, fontScale=lw/3.5, color=(255, 255, 255), thickness=tf, lineType=cv2.LINE_AA ) return image
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 # Function to plot images with the bounding boxes. def plot(image_path, label_path, num_samples): all_training_images = glob.glob(image_path+'/*') all_training_labels = glob.glob(label_path+'/*') all_training_images.sort() all_training_labels.sort() temp = list(zip(all_training_images, all_training_labels)) random.shuffle(temp) all_training_images, all_training_labels = zip(*temp) all_training_images, all_training_labels = list(all_training_images), list(all_training_labels) num_images = len(all_training_images) if num_samples == -1: num_samples = num_images plt.figure(figsize=(15, 12)) for i in range(num_samples): image_name = all_training_images[i].split(os.path.sep)[-1] image = cv2.imread(all_training_images[i]) with open(all_training_labels[i], 'r') as f: bboxes = [] labels = [] label_lines = f.readlines() for label_line in label_lines: label, x_c, y_c, w, h = label_line.split(' ') x_c = float(x_c) y_c = float(y_c) w = float(w) h = float(h) bboxes.append([x_c, y_c, w, h]) labels.append(label) result_image = plot_box(image, bboxes, labels) plt.subplot(2, 2, i+1) # Visualize 2x2 grid of images. plt.imshow(image[:, :, ::-1]) plt.axis('off') plt.tight_layout() plt.show()
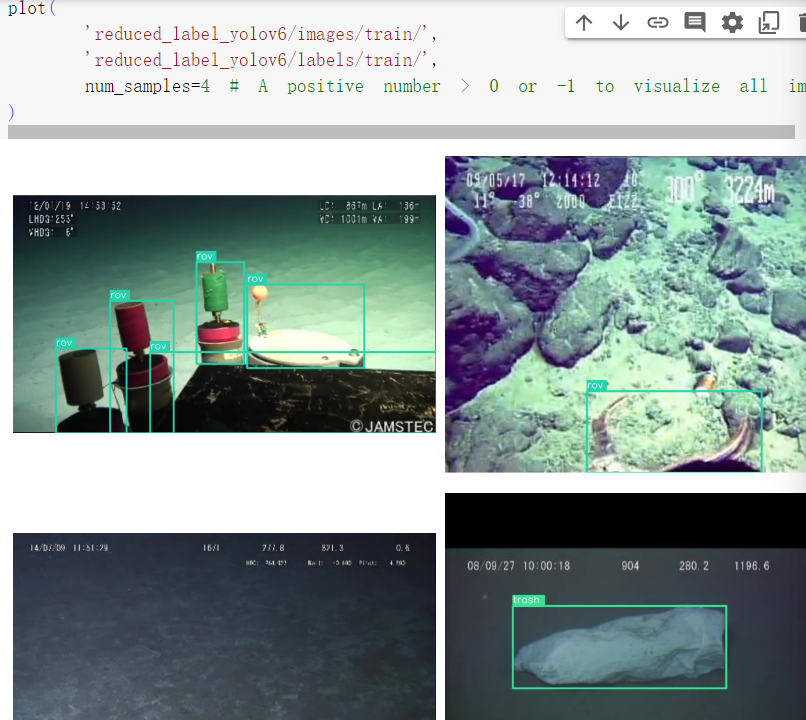
随机挑4张图片展示一下
1 2 3 4 5 plot( 'reduced_label_yolov6/images/train/', 'reduced_label_yolov6/labels/train/', num_samples=4 # A positive number > 0 or -1 to visualize all images. )
这个应该是权重的设置
1 os.makedirs('weights', exist_ok=True)
YOLOv6仓库权重的下载。注意:这个是于2023-6-22的YOLOv6仓库下载的最新权重,0.4.0版本,在运行这段代码前,请去仓库看一下权重文件是否更新,如果更新,请将链接更换一下。
1 2 3 4 5 6 # Comment / Uncomment the following lines to download the corresponding weights. !wget https://github.com/meituan/YOLOv6/releases/download/0.4.0/yolov6n.pt -O weights/yolov6n.pt !wget https://github.com/meituan/YOLOv6/releases/download/0.4.0/yolov6s.pt -O weights/yolov6s.pt !wget https://github.com/meituan/YOLOv6/releases/download/0.4.0/yolov6l.pt -O weights/yolov6l.pt
OK,万事大吉,可以开始训练模型了。
模型训练 训练模型需要这个代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # Train YOLOv6n model. !python tools/train.py \ --epochs 25 \ --batch-size 32 \ --conf configs/yolov6n_finetune.py \ --data data/underwater_reduced_label.yaml \ --write_trainbatch_tb \ --device 0 \ --eval-interval 1 \ --img-size 640 \ --name v6n_32b_640img_100e_reducedlabel ############################################################## # Train YOLOv6s model. # !python tools/train.py \ # --epochs 100 \ # --batch-size 32 \ # --conf configs/yolov6s_finetune.py \ # --data data/underwater_reduced_label.yaml \ # --write_trainbatch_tb \ # --device 0 \ # --eval-interval 1 \ # --img-size 640 \ # --name v6s_32b_640img_100e_reducedlabel ############################################################## # Train YOLOv6l model. # !python tools/train.py \ # --epochs 100 \ # --batch-size 32 \ # --conf configs/yolov6l_finetune.py \ # --data data/underwater_reduced_label.yaml \ # --write_trainbatch_tb \ # --device 0 \ # --eval-interval 1 \ # --img-size 640 \ # --name v6l_32b_640img_100e_reducedlabel
训练参数
--epochs:要训练的时期数。--batch-size:一批数据中的训练样本数。--conf:要使用的模型配置。我们正在使用 这里,它已经随 YOLOv6 存储库一起提供,用于微调目的。yolov6n_finetune.py--data:数据集 YAML 文件。--write_trainbatch_tb:这是一个布尔参数,表示我们要将日志写入 TensorBoard。--device:这将占用 GPU 设备 ID。当我们运行多 GPU 训练时,该值为 0,1(逗号后没有空格)。--eval-interval:运行评估的周期数。我们在每个纪元之后运行评估。pycocotools--img-size:用于训练的图像大小。--name:项目目录名称。给出一个合适的名称将有助于轻松区分训练实验。
我这里训练的时期数是25,训练了一个半小时
这是我训练一个时期的效果,刚开始可以先将时期数设为1,跑通一遍试试手。
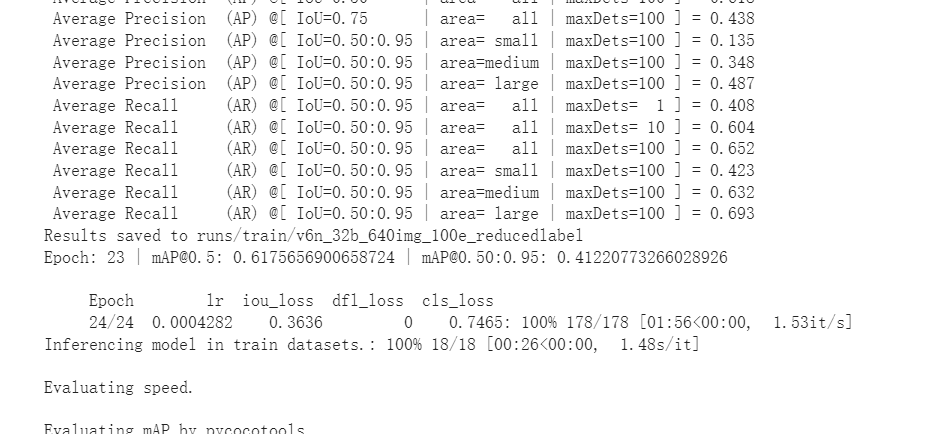
这是25个时期的效果
可以看出lr,iou_loss,cls_loss还是降低不少呢
时期设置到100会训练的更好,我害怕时间太久,谷歌硬盘不保存,所以我就训练了25个时期,官方说是可以一次运行12个小时,所以100个时期应该也没问题。
看到这一行了吧
还记得这张图片吧
它的输出信息是0,所以我们这里填0 ,如果你有两块GPU,那么你可以这样填
注意了!
如果你第一遍没有跑通,或者第一遍跑通了,或者因为报错调试着跑了好几遍,那么你的/content/drive/MyDrive/YOLOv6/runs/train文件夹中将会多出很多v6n_32b_640img_100e_reducedlabel文件,比如v6n_32b_640img_100e_reducedlabel,v6n_32b_640img_100e_reducedlabel1,v6n_32b_640img_100e_reducedlabel2,v6n_32b_640img_100e_reducedlabel3,等等
我这里就剩一个v6n_32b_640img_100e_reducedlabel,其他的我已经删过了
如果你第一次没有跑通,会生成v6n_32b_640img_100e_reducedlabel文件夹,也许你在v6n_32b_640img_100e_reducedlabel5中跑通了模型(第五次跑)。这时候如果你想接着继续运行下面的代码,将会报错。因为下面的代码是读取的v6n_32b_640img_100e_reducedlabel这个文件夹里的文件(根据下一条代码的配置),v6n_32b_640img_100e_reducedlabel5里面有正确的文件,但是它读取不到,这时候需要你手动调整一下文件名了(或者改一下下一条代码的配置)。
比如删除掉没有跑通的模型的文件夹
1 !rm -rf /content/drive/MyDrive/YOLOv6/runs/train/v6n_32b_640img_100e_reducedlabel
然后将你正确的模型文件的文件夹重命名为v6n_32b_640img_100e_reducedlabel
你需要保证你的顺利跑通的模型在名为v6n_32b_640img_100e_reducedlabel的文件夹下。
然后你就可以运行下面的代码了。
这是你调best_weights参数的代码,我上面说的是一种方法,但更好的应该是也在这里面调整,将你顺利跑通的模型放在这里面就可以了,这样你可以保存多个模型了。如果你跑好的模型是v6n_32b_640img_100e_reducedlabel5,就需要在下面的v6n_32b_640img_100e_reducedlabel后面加个5就ok了,这样可以指定生成的模型了。
1 2 3 4 result_dir = os.path.join( 'runs', 'train', 'v6n_32b_640img_100e_reducedlabel' ) best_weights = os.path.join(result_dir, 'weights', 'best_ckpt.pt')
接下来是在验证图形上进行推理了
1 2 3 4 5 6 # Run the inference on the validation images. !python tools/infer.py \ --weights {best_weights} \ --yaml data/underwater_reduced_label.yaml \ --source reduced_label_yolov6/images/valid/ \ --name v6n_infer_valid__images
推理好的图片将会放在这里
定义展示图片的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def visualize(res_dir): """ Shows a 2x2 of images. """ plt.figure(figsize=(15, 12)) all_images = glob.glob(os.path.join(res_dir, '*')) for i, image_path in enumerate(all_images): if i == 4: break image = cv2.imread(image_path) plt.subplot(2, 2, i+1) plt.imshow(image[:, :, ::-1]) plt.axis('off') plt.tight_layout() plt.show()
随机出四张图片看看效果
1 visualize('runs/inference/v6n_infer_valid__images/')
结束 我的代码所在的仓库链接crwhsh/YOLOv6-Underwater_Trash_Detection (github.com) 基于YOLOv6-水下垃圾检测 | one hu的博客













 wechat
wechat alipay
alipay
